In this section
TIMBUS Partners









Making Research Approaches Sustainable
- Details
- Created on Thursday, 07 November 2013 16:54
- Last Updated on Tuesday, 21 October 2014 08:32
|
|
Elisabeth Weigl, Secure Business Austria "Although I performed the processes now modeled merely two years ago and repeated their execution multiple times, it was partly difficult to recover the exact steps taken back then." |
|

![]()
An important issue we deal with in TIMBUS is to preserve processes and the knowledge that underlies them. When I did my master’s thesis I tried to recreate the setup of experiments described in published papers in order to use them for my own experiments. The information found in the papers was insufficient for this task and although the authors could help with some questions, some of the information was lost and I was only able to generate a similar but not identical environment, with which I was not able to reproduce the published results exactly. The attempt to retrieve the lost information was costly and still did not succeed. It would have been good if I had preserved the complex process of my own thesis’ experiments in a structured manner, so that somebody else, who wanted to reuse my research and who was not involved in the work could redo all steps unaided. However, when I finished the thesis I did not think about the preservation of the process steps.
Now, two years later, we are working on the TIMBUS context model. As the context model can be used to describe a process in such a way as to enable another person to understand it as well, I decided to finally model my master’s thesis. The context model is suitable for this task because it focuses, on the one hand, on the redeployment of the process and, on the other hand, on the understanding of the purpose of the process. It is based on the ArchiMate Enterprise Architect modeling language, with which all relevant aspects of an organization and of IT systems can be captured. However, not all of the context information required for preservation can be modeled with ArchiMate, which is why it needs to be extended by domain specific aspects. More information on the context model can be found in a previous post /portal/blogs-news-items-etc/timbus-blogs/166-context-modelling-and-archimate/. The benefit of the context model is the modeling of different process layers, namely the business, application, and technology layer. For my thesis’ model the business layer gives an overview of the steps that need to be taken. Through the application layer these steps are linked to the relevant programs or files represented in the technology layer. With this a broad overview of everything necessary to redo the setup and experiments done in the thesis should be possible and, where required, domain specific information can be provided, such as on file formats used, software licenses required, etc.
The master’s thesis is set in the Information Retrieval domain and named “Mitigating the Bias of Retrieval Systems by Corpus Splitting – An Evaluation in the Patent Retrieval Domain”[1]. The goal was to work with different patent indexes to make documents with poor findability more retrievable. Because of these multiple indexes and the necessary ground truth creation, the setup was rather complex and contained many steps. Three different retrieval engines were used to compare the results, which scaled up the complexity again. Because many small programs were implemented for various parsing or format conversion steps it was difficult to remember their purpose and their exact place in the process sequence.
When I finished my master’s thesis I had to delete some of the used material, especially the indices that were using a lot of hard-disc space. Although I did not think of ever reusing the work, the basic files and information for an entire re-implementation were saved. However, I had to recover the dependencies between the different steps, respectively programs, and rediscover in which sequence they had to be done.
The first step of modeling the process is to create an instance of the DIO, the domain independent ontology, which captures high-level concepts of the process. When recovering the process I started with looking in the written publication where general process steps were noted. The most important information was there, however it was difficult to remember all relations between the steps. Thus I began with different scratches of the process flow. I started with a business layer of the whole project, including all process steps necessary to redo the retrieval experiments. The technology and then the application layer followed. Because it was difficult to keep track of all the relations between different objects, the decision was made to split the overall view into three different views: the preparational work, the ground truth creation, and the general view. The preparational work view includes filtering out the patents with which the experiments have to be done and converting them to a format applicable for the retrieval engines. The preparational view and the ground truth creation view have to be done at first and only once and can thus be separated out from the general overview.
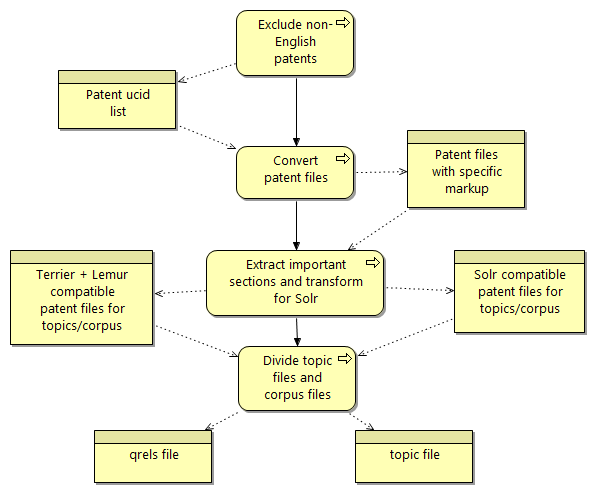
Business layer of the “Preparational work view”
The next step was to refine my model with specific concepts described by the DSOs, the domain specific ontologies of the context model. For example, one can describe all the formats of files used in the process, for instance indexer files, text files, or xml files, by the means of the PREMIS DSO, which allows us to detail what file format an artifact has, and where this file format itself is described (e.g., in a registry, such as PRONOM).
Although I performed the processes now modeled merely two years ago and repeated their execution multiple times, it was partly difficult to recover the exact steps taken back then. Part of this was due to the fact that the information needed for this recovery was not backed up along with the data objects. Thus some information had to be deduced, for instance the usage of two programs called “parser” (which were actually a converter and an extraction program). For another person who did not work on this project it may be impossible to recover all of the steps done for the thesis.
Thus the modeling showed exactly the problem we want to tackle with our work in TIMBUS. For the process owner information about the process is self-evident, and many small but important details seem obvious and might be omitted in a textual description. But even for the owner, documenting a previously executed process is not a trivial task. The overall goal of the process documentation is that a third person, who has no previous knowledge about the process, is enabled to understand it. For instance, when publishing research, another researcher should be able to understand and repeat the steps necessary for the published results. The context model is able to make the previously self-evident information more explicit to the third person.
By using the context model one is able to preserve knowledge about a process in order to support a third person in re-implementing the process steps to re-run experiments and receive the same results as in the published work. Thus, a context model of the experiments performed in the initial phase of the thesis, when I had to recreate the experiment setup, would have also helped me regarding the understanding of the different steps needed.
